分布式一致性协议 - Gossip
条评论前面我们讲过CAP定理、Paxos、Raft,那么试想几个场景:
- 我们要实现一个完全的AP系统。即集群中只有一个节点存活,也能向外提供服务。在此基础上,我们如何保证数据最终一致性?
- 在一个庞大的集群中,对某个数据修改后,如何同步到其他节点?
- 在一个去中心化的集群中,各节点都是对等节点。如何同步数据,使保证各节点数据达到一致?
答案就是gossip协议,gossip是一种去中心化的分布式协议,用于实现节点之间的信息交换,大名鼎鼎的bitcoin也使用了gossip来传播交易和区块信息。在分布式系统中,也用它来实现最终一致性,比如cassandra、redis。
六度分隔理论
循源,需从六度分隔理论开始。六度分隔理论,简单地说:“你和任何一个陌生人之间所间隔的人不会超五个。”也就是说,最多通过六个人你就能够认识任何一个陌生人。(小声嘀咕)你老婆最多拖6个人的关系就能认识到你的任何一个P(朋)友。
数学解释如下:
若每个人平均认识260人,其六度就是260^6=308,915,776,000,000。消除一些节点重复,那也几乎覆盖了整个地球人口若干多多倍。
基于六度分隔理论,任何信息的传播其实非常迅速,而且网络交互次数不会很多。Facebook研究了已注册的15.9亿使用者资料,发现“网络直径”为是4.57,即每个人与其他人间隔为4.57人。
gossip原理
gossip英文原意:流言蜚语。gossip协议就像流言蜚语一样,利用随机的,带有传染性的方式,将数据传遍整个网络。即在一定时间内,完成数据一致性。
gossip传播方式分为两种:反熵、谣言传播。有的也认为可分为三种:直接邮寄、反熵、谣言传播。所增加的直接邮寄,是指当数据有修改时,直接把数据发送给其他节点,即写时完成数据一致。而反熵、谣言传播则是通过异步方式修复节点之间数据一致。
gossip将各节点分为三类感染状态。
- susceptible (S): The node does not know about the update
- infected (I): The node knows the update and is actively spreading it
- removed (R): The node has seen the update, but is not participating in the spread-
ing process (in epidemiology, this corresponds to death or immunity)
gossip原文中,有一些含义相近的词,我们列出来可能更好理解:
反熵:Anti Entropy、error correction、SI
谣言传播:Rumor-Mongering、update spreading、SIR
例如下文:
In Section 1.2.1 we identified two sub-problems, namely update spreading and error correction.The former is implemented by an SIR gossip protocol, and the latter by an SI protocol.
The SIR gossip is called rumor mongering.
The SI algorithm for error correction is called anti-entropy.
Anti-Entropy(反熵)
先解释反熵这个词,熵是物理中指体系的混乱程度。反熵在这里的意思,也是指修复集群中混乱程度,即修复数据一致。
gossip原文中描述:用于纠错的SI算法称为反熵。这里的SI算法,是指节点只有两种状态:susceptible(未被感染)、infected(已感染)。注意每个节点都可以同时扮演这两个角色,当A把数据推给B时,A为infected,B为susceptible。当A向B拉取数据时,A为susceptible,B为infected。
具体描述反熵的传播过程,则是每个节点周期性地随机选择其他节点,然后通过互相交换自己的所有数据来消除两者之间的差异,直到整个网络中节点数据一致。
实现反熵的方式主要有三种:推、拉、推拉。推则是将自己数据推给对方,更新对方的数据。拉则是拉取对方的数据,更新自己数据。推拉即更新自己和对方的数据。
伪代码实现

伪代码中围绕两个boolean变量:push、pull,表示同步消息模式。运行过程可分为两个线程理解:
- 异步消息同步线程,即消息同步入口,每个∆时间单位执行一次。
- 消息处理线程,即接收到消息,进行处理。
- 本次数据同步发起者,记为A,A生成随机集合P。
- 如果是push模式,并且A处于infected,则A发送数据给集合P。
- 第11行,集合P收到数据,保存数据。同时意味着自己处于infected
- 如果是pull模式,则A发送请求更新的指令给集合P。
- 第15行,集合P收到请求更新的指令,如果自己处于infected,则发送第11行所保存的数据给A。
- A接收到数据,即第11行。
生产应用
算法描述中,虽然描述的是周期性的向其他节点交换数据来消除两者之间的差异。但是反熵在实际生产中的应用和原本的描述会有所出入,主要原因包含两点:
- 每次推送和拉取都是全量数据进行比较,性能消耗比较大。
- 可能出现极端情况(两个节点互相进行推拉,其他的节点也没有选择它们两进行推拉)导致某些节点数据可能达不到一致。
- 随机性的选择节点消除两者的差异,如果要整个集群节点都达到一致,所需时间不确定,也没有明确的标准表明集群中数据达到一致。
在实际应用场景中,不推荐采用随机的节点进行反熵。而是需要刻意的设计一个闭环,这样能在一个确定的时间范围内完成最终一致性,而不是基于随机的概率。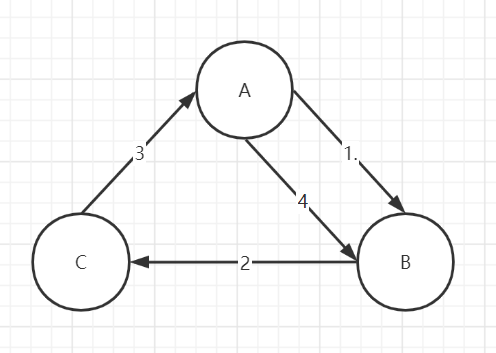
- 由A发起反熵,A的数据推给B,可以把A中包含的数据B中不包含的数据同步给B
- B的数据推给C,消除C中没有A、B的数据
- C的数据推给A,则可以消除A中没有B、C的数据
- A还需要再推一次给B,这样才能把C中的数据推给B
至此,完成数据的最终一致性。这里可以做一个优化:如果反熵每次都推送全量数据进行比较,太消耗资源。这里建议记录已完成一致性的数据,后续执行反熵,只推送增量数据。
Rumor-Mongering(谣言传播)
谣言传播,采用一传十,十传百的方式。指各节点周期性的,向随机的一组节点广播更新数据。其他节点收到更新的数据后,继续周期性的,向随机的一组节点广播更新数据,直到所有节点都处理了新数据。为了使谣言传播能够停止(避免广播风暴),gossip增加removed状态,当节点收到的谣言并且该谣言处于removed(之前已经处理过的谣言)时,该节点将不继续传播该谣言。即SIR算法。
传播示例
在一个集群中,发生了数据更新,即为infected状态。图片最开始只有一个节点有数据更新,由它周期性的外向外广播谣言,其每次广播数量为2,该参数即为fanout=2。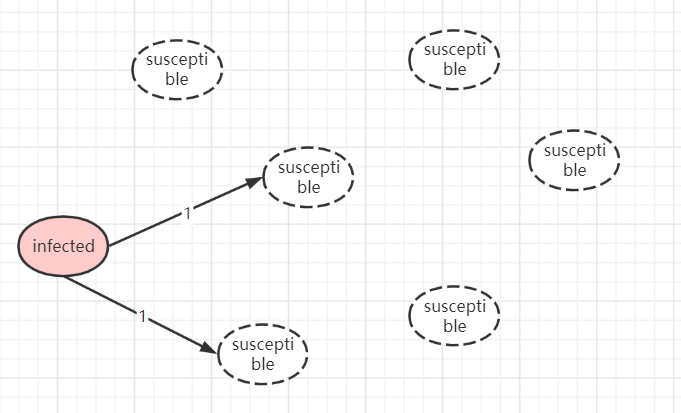
当其他susceptible,收到数据后,变更自己为infected状态,继续向外广播谣言。直到完成数据最终一致性。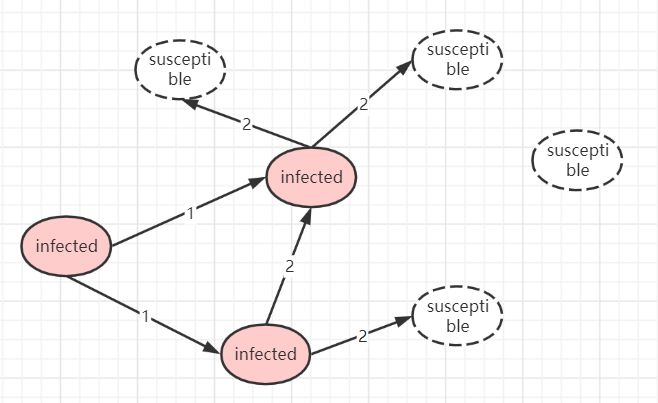
谣言传播属于指数级的传播,我们得到:传播所需周期与fanout(记为f)之间的关系式。当节点数量为N时,有:$log_f{N}$。
当集群中存在10000个节点时,每次传播感染5个。有:$log_5{10000}$ = 5.72。得出最理想的情况,5.72次传播即可感染10000个节点。该公式为最理想情况,实际传播过程中,可能会出现某一个节点被感染多次。
伪代码实现
在gossip论文中,提供的伪代码实现中,主要增加了不继续传播的条件。
- 本次数据同步发起者,记为A,A生成随机集合P。
- 如果是push模式,并且A处于infected,则A发送更新数据给集合P。
- 集合P收到更新数据,第16行,判断是否已处理该数据,则返回feedback给A。
- 如果处理,则保存该更新数据。同时意味着自己处于infected
- 如果是pull模式,则发送请求更新的指令给集合P。
- 第23行,集合P收到请求更新的指令,如果自己处于infected,则发送第19行所保存的更新数据给A。
- A接收到更新数据,即第15行。
- A收到feedback消息,通过概率切换到removed
生产应用
谣言传播,可以快速的向网络中广播,非常具有传染性,适合节点数量多、集群庞大的网络中更新数据。由于集群中都是对等节点,它比较适合动态变化的分布式系统。
但是为了方便谣言传播,发送的数据包不能太大,主要用于新数据增量更新。
优劣
gossip的优势很明显,具体总结,可有以下几点:
- 简单有趣
- 可扩展、容错:由于各节点之间对等性,允许节点之间任意的增加和减少。
- 天然的去中心化
- 传播速度快,适用于非常庞大的集群
劣势:
- 达成最终一致性的时间不确定性
- 消息延迟,只能实现最终一致性,传播过程中,数据不一致
- 广播rpc消息量大,对网络压力
- 拜占庭将军问题,不允许存在恶意节点
做几个小题目吧
1 | 文章开始的三个小题目,你有答案了吗? |
- 本文链接:https://www.ofcoder.com/2020/11/24/theory/%E5%88%86%E5%B8%83%E5%BC%8F%E4%B8%80%E8%87%B4%E6%80%A7%E5%8D%8F%E8%AE%AE%20-%20Gossip/
- 版权声明:Copyright © 并发笔记 - ofcoder.com. Author by far.
分享