分布式一致性协议 - Paxos
条评论paxos 科普
分布式算法,不得不提paxos。它是目前公认的解决分布式共识问题最有效的算法之一,甚至可以说过去几十年里一切分布式一致性算法都来源于它。
那么要学习paxos,我们首先得认识它。一般描述它,都会包含两个词:分布式容错、分布式共识算法。那么它们是指什么呢?paxos又解决了什么样的问题呢?
- 分布式容错
分布式容错,是指在分布式环境下,能够容忍一部分节点宕机,还能向外提供稳定的服务。 - 分布式共识算法
分布式共识算法,是指在分布式环境下,各个节点能就某个值达成共识,即所有节点都认同某个值。
理解共识可能要难一点,那么我举个例子。假如有A、B两个客户端,他们都对同一个X进行赋值。A需要设置X=1,B需要设置X=2。那么让A和B都认同值X=1或者X=2的过程,就是达成共识。
带着这个问题,来聊聊如何达成共识呢?
初探paxos
paxos为了帮我们理解,抽象出三个角色和两个阶段
- 角色:提案者(proposer)、接受者(acceptor)、学习者(learner)
- 阶段:prepare阶段、accept阶段、learn阶段
提案(proposal)
在描述这些角色之前,我们需要先了解什么提案。在paxos算法中提案是指需要达成共识的某一个值,或者某一个操作。paxos对其封装成一个提案,并为其生成唯一的提案编号。本文中使用[M, V]表示一个提案,其M表示提案编号,V表示需要达成共识的值。
提案者(proposer)
proposer的工作在于接收客户端请求,将其封装成提案(proposal)。并将提案(proposal)发给所有的接受者(acceptor)。根据接受者(acceptor)返回情况,控制是否需要提交该提案(proposal)即保存该提案(proposal)。
接受者(acceptor)
acceptor的工作在于参与对提案(proposal)的投票,接收和处理paxos的两个阶段的请求。
学习者(learner)
learner不参与提案和投票,只被动接收提案结果。他的存在可用于扩展读性能,或者跨区域之间读操作。
因为他们不投票,所以他们不是paxos集群的重要组成部分。因此,它们可以失败,或者与集群断开连接,而不会损害paxos服务的可用性。对用户的好处是learner相比acceptor来说更能通过不太可靠的网络链接进行连接。实际上,learner可用于与另一个数据中心的paxos服务器通信,并且写入消耗最小的网络流量,因为在没有投票协议的情况下所需的消息数量较少。
prepare阶段
prepare阶段,由proposer向acceptor发送prepare请求,acceptor根据约定决定是否需要响应该请求。如果acceptor通过提案[M, ]的prepare请求,则向proposer保证以下承诺
- acceptor承诺不再通过编号小于等于M的提案的prepare请求
- acceptor承诺不再通过编号小于M的提案的accept请求,也就是不再通过编号小于M的提案
- 如果acceptor已经通过某一提案,则承诺在prepare请求的响应中返回已经通过的最大编号的提案内容。如果没有通过任何提案,则在prepare请求的响应中返回空值
其中prepare阶段还得注意,在prepare请求中,proposer只会发提案编号,也就是[M, ]。
accept阶段
accept阶段,在proposer在prepare阶段收到大多数响应后,由proposer向acceptor发送accept请求。例如此时进行决策的提案是[M, V],根据acceptor在prepare阶段对proposer的承诺。
- 如果此时acceptor没有通过编号大于M的prepare请求,则会批准提案[M, V],并返回已通过的编号最大的提案(也就是[M, ])。
- 如果此时acceptor已经通过编号大于M的prepare请求,则会拒绝提案[M, V],并返回已通过的编号最大的提案(大于M的编号)。
proposer会统计收到的accept请求的响应,如果响应中的编号等于自己发出的编号,则认为该acceptor批准过了该提案。如果存在大多数acceptor批准了该提案,则记作该提案已达成共识,或者记作提案已被批准。如果没有大多数acceptor批准该提案,则重新回到prepare阶段进行协商。
其中accept阶段也有注意的地方,在prepare请求中,proposer只会发提案[M, ]。而accept请求,proposer会发送提案编号和提案值,也就是[M, V]。这里要注意的是V的值,如果在prepare请求的响应中,部分acceptor已经批准过的提案值,则V为prepare请求的响应中编号最大的提案值,否则可以由proposer任意指定。
learn阶段
learn阶段,在某一个提案通过paxos达成共识之后,由acceptor通知learner学习提案结果。
算法陈述
该小节分为两部描述:提案选定、提案获取。
- 提案选定,是描述paxos从一个提案的产生到如何达成共识的过程。也就是prepare阶段、accept阶段
- 提案获取,是描述learner如何获取保存提案,也就是learn阶段
提案选定
先来看一张非常流行的图,它用伪代码描述了paxos的过程。我预先描述下几个变量。
- minProposal:当前acceptor在prepare请求中通过的最大提案编号
- acceptedProposal:当前acceptor在accept请求中通过的最大提案编号
- acceptedValue:当前acceptor在accept请求中通过的最大提案编号的提案值

- 先为proposal生成一个编号n,这里需要保证编号全局唯一,并且全局递增,具体实现全局编号,这里不予讨论。
- proposer向所有acceptors广播prepare(n)请求
- acceptor比较n和minProposal,如果n>minProposal则执行minProposal=n,并且将 acceptedProposal 和 acceptedValue 返回给proposer。
- proposer接收到过半数回复后,如果发现有acceptedValue返回,将所有回复中acceptedProposal最大的acceptedValue作为本次提案的value,否则可以任意决定本次提案的value。
- 到这里可以进入第二阶段,广播accept (n,value) 到所有节点。
- acceptor比较n和minProposal,如果n>=minProposal,则acceptedProposal=minProposal=n,acceptedValue=value,本地持久化后,返回;否则,返回minProposal。
- proposer接收到过半数请求后,如果发现有返回值result(minProposal) > n,表示有更新的提议,跳转到1;否则value达成一致。
当然,实际运行过程中,没有以上陈述的那么理想。真实情况下,每一个proposer都有可能产生多个提案,但只要每个proposal遵循如上算法运行,就一定能保证执行正确性。文章后续我们会对多提案提出的情况进行模拟,并详细讲解。
提案获取
在一个提案达成共识后,如何让learner获取该提案也是一个值得细究的问题。一般有以下几种方案。
- 方案一
最简单的方法就是一旦acceptor批准了一个提案,就将该提案发给所有的learner。这种做法虽然可以让learner尽快的获得被选中的提案,但是却需要每个acceptor与所有learner逐一进行通信,通信次数为二者乘积,所以效率较低。 - 方案二
选定一个主learner,如有某一个提案批准后,由acceptor通知主learner,当主learner被通知后,由它通知其他的learner。这个方案虽然多了一个步骤,但是通信次数大大降低,通信次数为learner的数量。该方案同时引出另一个问题:主learner随时可能出现故障。 - 方案三
在基于方案二的基础上,由单个主learner扩展成一个主learner集合。集合中learner数量越高,可靠性也越好。
算法模拟
为了更好的熟悉paxos,我们举例描述paxos中提案选定过程。假设存在3节点的paxos集群,这里需要注意每一个节点可以同时扮演proposer和acceptor。情况如下
proposerA收到请求将X设置成3,proposerB收到请求将X设置成5。proposerA和proposerB分别为此生成提案,其proposerA的提案编号为1,proposerB提案编号为2。在prepare阶段它们交互结果如下
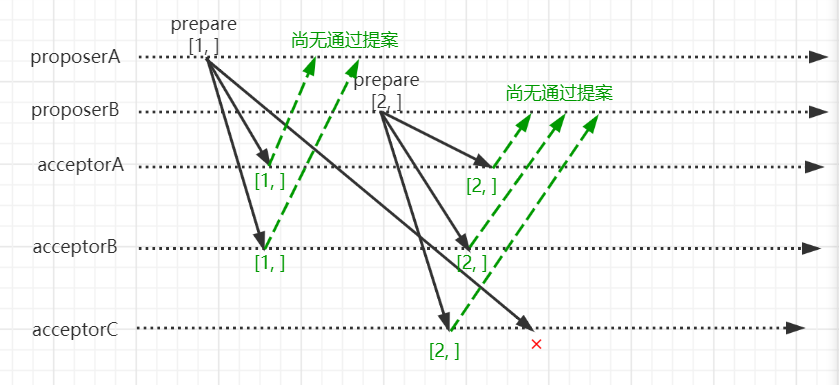
- proposerA和proposerB分别进入prepare阶段,将提案编号发给各个acceptor。
- acceptorA和acceptorB在收到proposerA的prepare请求后,由于没有通过过任何prepare请求,也没有批准过任何的accept请求。则给proposerA返回尚无提案。
- acceptorC由于在收到proposerB的prepare请求之后再收到proposerA的prepare请求,且proposerB的提案编号大于proposerA的提案编号,故不给proposerA返回prepare响应。
- acceptorA和acceptorB在收到proposerB的prepare请求后,由于之前收到proposerA的prepare请求,则比较各自的提案编号,由于proposerB的提案编号大于proposerA的提案编号,但是又没有通过任何的accept请求,则给proposerB返回尚无提案,并向proposerB保证前文所说的三个承诺。
至此,proposerA获得2个prepare响应,proposerB获得三个prepare
响应。即他们都获得了大多数节点的prepare响应,于是各自开始accept阶段提交。
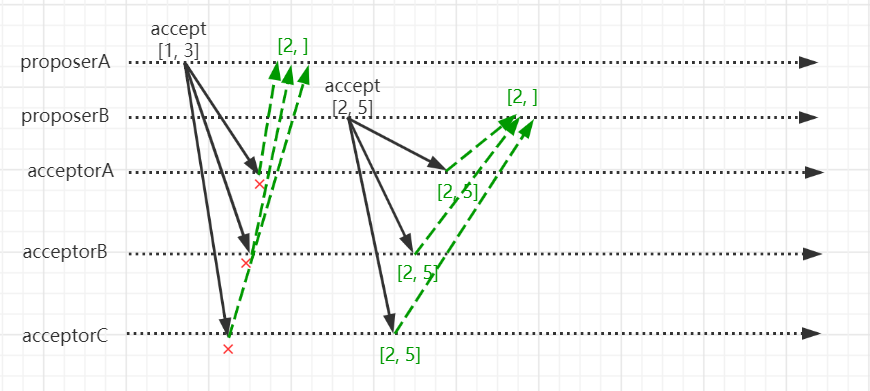
- proposerA由于收到的prepare响应中没有任何提案值,则自己任意设置提案值,也就是[1, 3]。并向各个acceptor发起accept请求。
- acceptorA、acceptorB、acceptorC收到proposerA的accept请求后,由于在prepare阶段,他们都向proposerB保证了上文所说的三个承诺,则他们不会该accept请求,并将prepare阶段通过最大的提案编号返回给proposerA,也就是[2, ]。
- proposerA收到[2, ]后,发现响应中的提案编号2比自己的提案编号1大,则认为没有accept通过该提案。proposerA需要重新回到prepare阶段进行协商。
- proposerB由于收到的prepare响应中没有任何提案值,则自己任意设置提案值,也就是[2, 5]。并向各个acceptor发起accept请求。
- acceptorA、acceptorB、acceptorC,在此期间没有通过任何的prepare请求也没有通过任何的accept请求,即同意批准该提案,返回[2, ]给proposerB。
- proposerB收到accept响应后,比对提案编号发现有大多数的提案编号是自己的编号,则认为该提案达成共识,完成协商过程。
以上过程的主要描述了accept对proposer的两个承诺,即如果acceptor通过提案[M, ]的准备请求
- acceptor承诺不再通过编号小于等于M的提案的prepare请求
- acceptor承诺不再通过编号小于M的提案的accept请求,也就是不再通过编号小于M的提案
那么还有一个承诺是
- 如果acceptor已经通过某一提案,则承诺在prepare请求的响应中返回已经通过的最大编号的提案内容。如果没有通过任何提案,则在prepare请求的响应中返回空值
为了描述该承诺,我们想象出这样一个场景。proposeB完成prepare请求后,发起accept请求,且提案为[3, 6]。在此过程中,proposeA发起prepare请求,提案编号为[4, ],并且acceptor先收到proposeA发起prepare请求,也就是说acceptor会拒绝proposeB的accept请求。情况如下
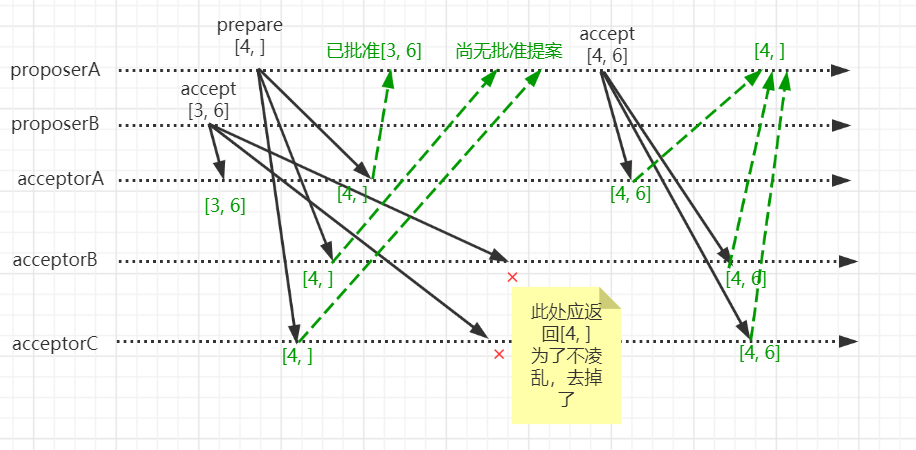
- proposerB发起accept请求,提案为[3, 6]。
- acceptorA收到proposerB的accept请求后,批准了该请求。
- proposerA发起prepare请求,提案为[4, ]。
- acceptorB、acceptorC先收到proposerA的prepare请求。则拒绝proposerB的accept请求。
- acceptorA收到proposerA的prepare请求,由于之前接收了proposerB发起accept请求,则给proposeA返回已批准的提案[3, 6]。
- 此时,proposerB重新进入prepare协商,proposerA收到大多数prepare响应,发起accept请求,由于收到acceptorA返回的提案[3, 6],那么proposer的提案值也只能为6,即[4, 6]。
- accept完成协商。
multi-paxos算法
原始的paxos算法(Basic Paxos),只能完成一个值的共识。Lamport宗师提到可以通过执行多次basic-paxos实现一系列值的共识。但是由于多次协商会增加通信以及影响协商的活性(指协商进入死循环)。
宗师则提出multi-paxos的解决方案,但是由于宗师并没有把multi-paxos讲清楚,只是介绍了大概的思想,缺少算法过程必要细节。所以这给了我们很大的想象空间,因此每个人实现的multi-paxos都有所差异。
总体来说multi-Paxos基于basic-paxos做了两点改进:
- 在所有Proposers中选举一个Leader,由Leader唯一地提交Proposal给Acceptors进行表决。这样没有Proposer竞争,解决了活锁问题。在系统中仅有一个Leader进行Value提交的情况下,Prepare阶段就可以跳过,从而将两阶段变为一阶段,提高效率。
- 针对每一个要确定的值,运行一次Paxos算法实例(Instance),形成决议。每一个Paxos实例使用唯一的Instance ID标识。
首先multi-Paxos是要选举一个leader的,宗师提到:可以通过basic-paxos进行leader的选举。
- 选举leader后,只能由leader提出proposal。
- 在leader宕机后,服务将临时不可用,等待leader重新选举。
- 在系统中仅有一个leader进行proposal提交的情况下,prepare阶段可以跳过。
multi-paxos通过改变prepare阶段的作用范围至后面leader提交的所有实例,从而使得leader的连续提交只需要执行一次prepare阶段,后续只需要执行accept阶段,将两阶段变为一阶段,提高了效率。为了区分连续提交的多个实例,每个实例使用一个instance ID标识,instance ID由leader本地递增生成即可。
multi-paxos允许有多个自认为是leader的节点并发提交proposal而不影响其安全性,这样的场景即退化为basic-paxos。
paxos回顾,思考几个题目吧
1 | 怎么解决两个提案提出后陷入死循环? |
参考文章:https://zhuanlan.zhihu.com/p/31780743。文中提到paxos推导过程,也可以了解下。
- 本文链接:https://www.ofcoder.com/2020/07/07/theory/%E5%88%86%E5%B8%83%E5%BC%8F%E4%B8%80%E8%87%B4%E6%80%A7%E5%8D%8F%E8%AE%AE%20-%20Paxos/
- 版权声明:Copyright © 并发笔记 - ofcoder.com. Author by far.
分享