谈谈分表分库常见问题解决方案
条评论本章的思路,是先讲讲根据业务增长进行分表分库,以及实现方案探讨,对这些方案产生的一系列问题该如何解决,以及现在社区中活跃的第三方分表分库中间件。
分表分库案例
互联网时代,每天都会产生海量的数据。我觉得每一位程序员都应该或多或少的了解到存储这个数据的解决办法,特别是小公司的程序员更应自己多尝试,多实践。因为在小公司,我们没有优秀的架构师,没有前辈的指引,更没有性能良好的设备来支持大数据计算。那么遇到数据到达瓶颈了怎么办?难道让业务不发展了?公司不挣钱了?所以特别是小公司的人更应该考虑。这是我个人的观点。
为什么不适用nosql/newsql?目前绝大部分公司的核心数据都是:以RDBMS存储为主,NoSQL/NewSQL存储为辅!互联网公司又以MySQL为主,国企&银行等不差钱的企业以Oracle/DB2为主!NoSQL/NewSQL宣传的无论多牛逼,就现在各大公司对它的定位,都是RDBMS的补充,而不是取而代之!
常用解决方案
常用分表分库的方案有很多
- 你可以自己实现物理的分库分表
- 常用数据库,如mysql有自己分表的解决方案,如:partitions
- 使用第三方中间件
这一节讲的就是自己实现物理分库分表,在分表之前,首先需要选择适当的分表策略,使得数据能够较为均衡地分不到多张表中,并且不影响正常的查询!
分表
对于互联网企业来说,大部分数据都是与用户关联的,因此,用户id是最常用的分表字段。因为大部分查询都需要带上用户id,这样既不影响查询,又能够使数据较为均衡地分布到各个表中(当然,有的场景也可能会出现冷热数据分布不均衡的情况),如下图: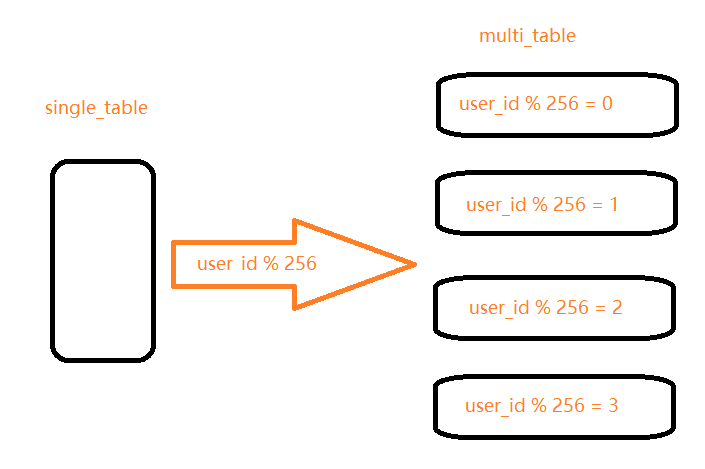
假设有一张表记录用户购买信息的日志表,由于日志记录条数太多,将被拆分成256张表。
拆分的记录根据user_id%256取得对应的表进行存储,前台应用则根据对应的user_id%256,找到对应日志存储的表进行访问。假如表结构如下
1 | order_log_( |
那么要查询用户id为257的日志,就先算法hash值(257 % 256 = 1),确定到那一张表再查询.
1 | select * from order_log_1 where user_id = 257; |
分库
对于分表来说,每张表的数据量是变小了,但是它们依然处于同一个数据库实例下,对于单个实例来说,吞吐量也是有限的。那么分库,你可以将多个schema部署在多个数据库实例上。如此的话,你需要在项目中配置多数据源,用来访问每个数据库实例,或者你也可以通过一个统一的微服务来做分表分库的路由。
与分表策略相似,分库可以采用通过一个关键字取模的方式,来对数据访问进行路由,如下图所示: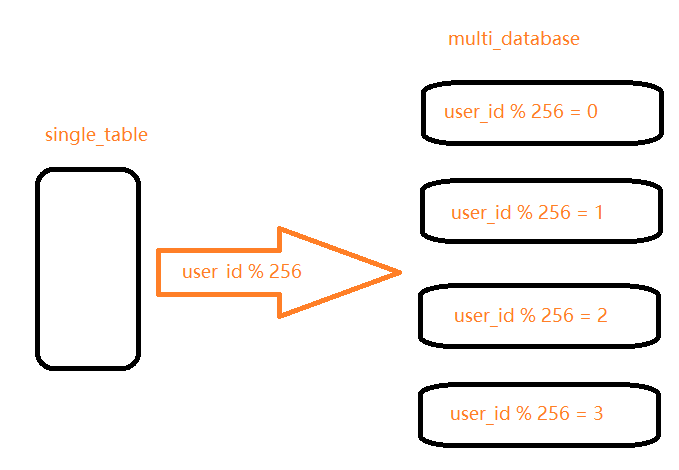
分表分库
有时数据库可能既面临着高并发访问的压力,又需要面对海量数据的存储问题,这时需要对数据库既采用分表策略,又采用分库策略,以便同时扩展系统的并发处理能力,以及提升单表的查询性能,这就是所谓的分库分表。那么这提供的一种策略就是:
- 中间变量 = user_id % (分库数量 * 每个库的表数量)
- 库 = 取整数 (中间变量 / 每个库的表数量)
- 表 = 中间变量 % 每个库的表数量
同样采用user_id作为路由字段,首先使用user_id 对库数量*每个库表的数量取模,得到一个中间变量;然后使用中间变量除以每个库表的数量,取整,便得到对应的库;而中间变量对每个库表的数量取模,即得到对应的表。
假设将原来的单库单表order拆分成256个库,每个库包含1024个表,那么按照前面所提到的路由策略,对于user_id=262145 的访问,路由的计算过程如下:
- 中间变量 = 262145 % (256 * 1024) = 1
- 库 = 取整 (1/1024) = 0
- 表 = 1 % 1024 = 1
这就意味着,对于user_id=262145 的订单记录的查询和修改,将被路由到第0个库的第1个order_1表中执行!
副作用解决方案
分库分表的好处显而易见,解决了数据存储容量的问题,但也带来了诸多弊端。这里简单的来分析,以及怎么解决
1. 如何能做到数据的平均拆分,防止某一库压力过大?
系统开发者要结合业务特点来确定分库分表键,比如以userID为分库分表键,采用hash取模的方式将数据散列到不同的库中。
但并不是所有场景都适合用userID作为分库分表键的,若存在“大卖家”,则该userID可能有很多条记录,若简单的按照上述方法进行拆分,则可能打爆其中一个数据库。
一般来说,会将一段时间以前的数据归档(比如某个userID三个月之前的数据),存放到类似HBase这种非关系型数据库中,以此来解决上述问题。
2. 分库分表之后就要求每个查询的where子句中必须携带分库分表键,但并非每个查询都能携带分库分表键的。
比如订单库按照订单号hash取模之后存储,此时分库分表键为订单号,那么想查询某位买家所有的订单,查询时就没有了分库分表键,就会出现“全表扫描”的情况。
一般在实践中解决这种问题的方法是建立“异构索引表”,即采用异步机制将原表内的每次一创建或更新,都换一个维度保存一份完整的数据表或索引表,拿空间换时间。
在上面说到,订单库按照订单号hash取模之后存储,同时也按照userID维度进行hash取模,再存储一份数据,那么想要获取某一userID的全部订单时,就将userID作为分库分表键传进去即可,避免了全表扫描。
第三方中间件
分库分表虽好,但是带来的一系列问题也是需要解决的。比如对开发人员要求增加、工作量的增加、同时bug量也会增加。那么这些问题肯定会有中间件来帮我解决的。这里只列举社区中比较有知名度的几个:
- 阿里的 TDDL、DRDS和cobar
- 开源社区的sharding-sphere
- 民间的mycat
以及还有,360的Atlas、美团的zebra。具体中间件怎么使用,大家可以各自去了解。这么多的分库分表中间件全部可以归结为两大类型:
- CLIENT模式
- PROXY模式
CLIENT模式代表有阿里的TDDL,开源社区的sharding-jdbc(sharding-jdbc的3.x版本即sharding-sphere已经支持了proxy模式)。PROXY模式代表有阿里的cobar,民间组织的MyCAT。无论是CLIENT模式,还是PROXY模式。几个核心的步骤是一样的:SQL解析,重写,路由,执行,结果归并。
- 本文链接:https://www.ofcoder.com/2019/04/21/java/%E8%B0%88%E8%B0%88%E5%88%86%E8%A1%A8%E5%88%86%E5%BA%93%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E5%86%B3%E6%96%B9%E6%A1%88/
- 版权声明:Copyright © 并发笔记 - ofcoder.com. Author by far.
分享