SQL反模式03-单纯的树
条评论设想你正在开发一个新闻网站,读者可以对文章评论,甚至相互回复,这样一来这个树就会延伸出很多分支,其深度也会大大增加,你选择一个简单的方案来实现需求:每条评论引用它所回复的评论。
1 | CREATE TABLE comments( |
这样一来,程序逻辑变得清晰明了,但是它并不能完成一棵树最基本的功能,就是遍历一整棵树
目的(分成存储与查询)
递归关系的数据很常见,数据会像树或以层级方式组织,比如:
- 组织机构图:职员与经理关系,每个职员有一个经理,同时经理也是一个职员
- 线程化讨论:像引言中介绍的评论链。
本篇对树结构定义:
- 最上层的节点叫做根(root)节点,它没有父节点
- 最底层的没有子节点的节点叫做叶(leaf)
- 中间的节点简单地称为非叶节点(nonleaf)
反模式(总是依赖父节点,邻接表)
最简单的方式就是添加parent_id,引用同一张表的其他条目,这样的设计也叫做邻接表,如下:
1 | CREATE TABLE comment( |
以下展示一个树结构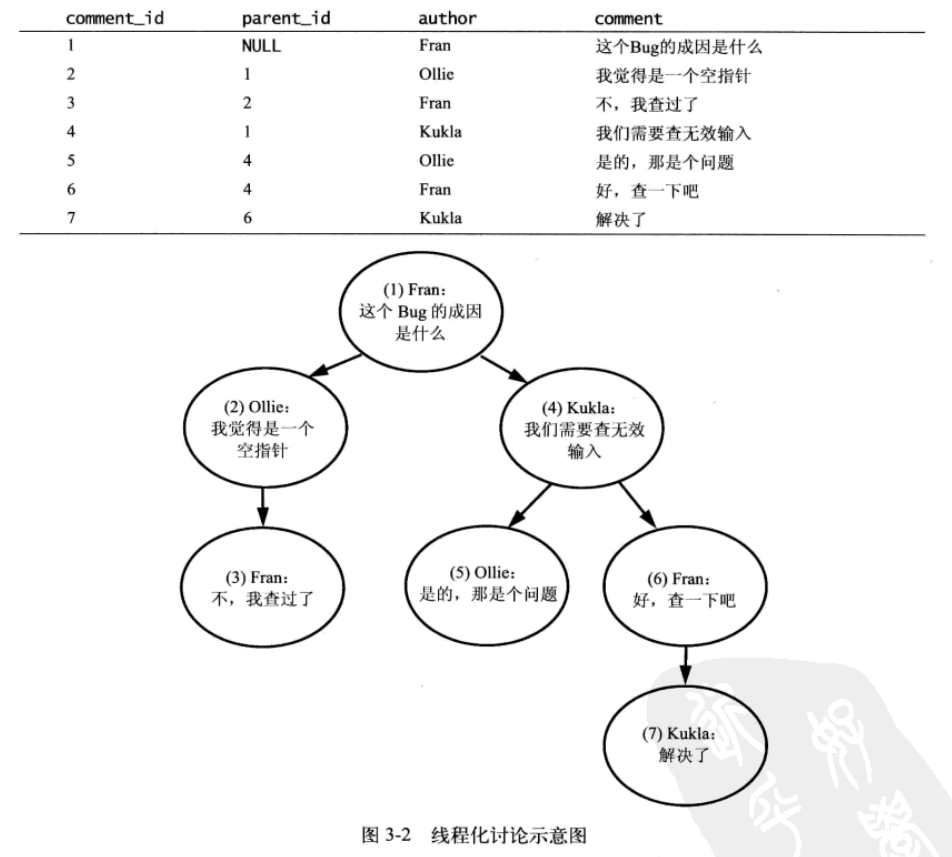
1.使用邻接表查询树
在引言中提到,邻接表不能完成一棵树最基本的查询:虽然你可以使用关联查询出某一个节点的子节点,如下:
1 | select c1.*, c2.* from comment c1 |
但是,这个查询只能获取两层,如果要继续查询某个节点的孙子,就的再关联一层。但是树的深度是无止境的。
另外还有一种办法,查询出所有的评论,然后再Java中重新构造这个树,但是大量的数据赋值,这是非常低效的。
2.使用邻接表维护树
插入修改节点:使用邻接表,是非常简单
1 | INSERT INTO comment(parent_id, bug_id, author, comment) |
删除节点:但是删除节点会变得复杂,你必须从该节点下最低级子节点开始删除,以保证外键完整性
1 | select comment_id from comment where parent_id = 4 -- return 5 and 6 |
这里虽然可以使用带 ON DELETE CASCADE 来修改外键,来使它自动完成以上操作。但是,如果需求是删除一个非叶子节点,并提升它的子节点,或将它子节点移动到另一个节点,如下:
1 | -- 查出自己的父节点 |
如何识别反模式
当你说过以下话,你可能正在使用“反模式”
- 我们的数结构要支持多少层
- 我们总是很害怕接触那些管理树结构的代码
- 我需要一个脚本来定期的清理树中的孤立节点数据
合理使用反模式
- 邻接表设计的优势在与能快速地获取一个给定节点的直接父子节点,也很容易插入新节点、维护节点、删除节点。如果树的分层结构不是很深,可以使用这种模式。
- 某些数据库提供了递归查询,可是使用WITH关键字来查询,
1
2
3
4
5
6
7
8
9
10
11
12
13
14-- SQL Server 2005, Oracle 11g, IBM DB2, PostgreSQL 8.4
with CommentTree(comment_id, parent_id, bug_id, author, comment_date, comment)
as (
select * 0 as depth from comment
where parent_id is null
union all
select c.*, ct.depth+1 as depth from CommentTree ct
join comment c on ct.comment_id = c.parent_id
)
select * from CommentTree where bug_id = 1234;
-- Oracle 9i 和 10g 递归查询
select * from comment
start with comment_id = 9876
connect by prior parent_id = comment_id
解决办法:使用其他树模型
1.路径枚举:
用一个path字段保存当前节点的最顶层的祖先到自己的序列(路径)
1 | CREATE TABLE comment( |
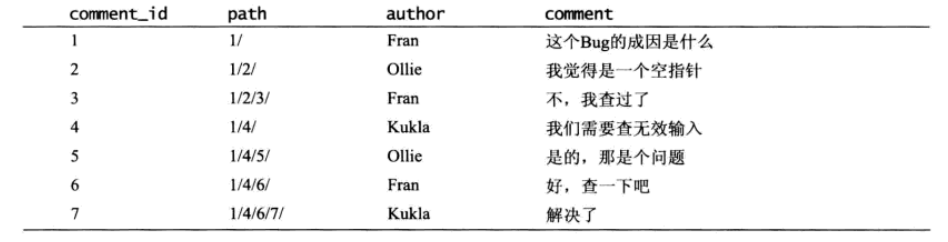
查询评论#7(路径是1/4/6/7),的祖先
1 | select * from comment where '1/4/6/7' like path || '%'; |
查询评论#4(路径是1/4),的子孙
1 | select * from comment where path like '1/4/' || '%'; |
查询评论#4,每个用户的评论数
1 | select count(1) from comment where path like '1/4' || '%' |
插入也简单
只需要将父节点的path查出来,再追加自己的id就行了,但是一般id是自增,你需要先insert子节点,再select父节点,再update子节点
总结:
- 优点:查询方便
- 缺点:
- 存在“乱穿马路”,不能保证存储的值的有效性。
- 修改节点,比较麻烦,所有子节点的path也要修改
2.嵌套集:
存储子孙节点的相关信息,而不是节点的直接祖先。
1 | CREATE TABLE comment( |
要求:nsleft的数值小于该节点所有后代的id,nsright的数值大于所有后代的id。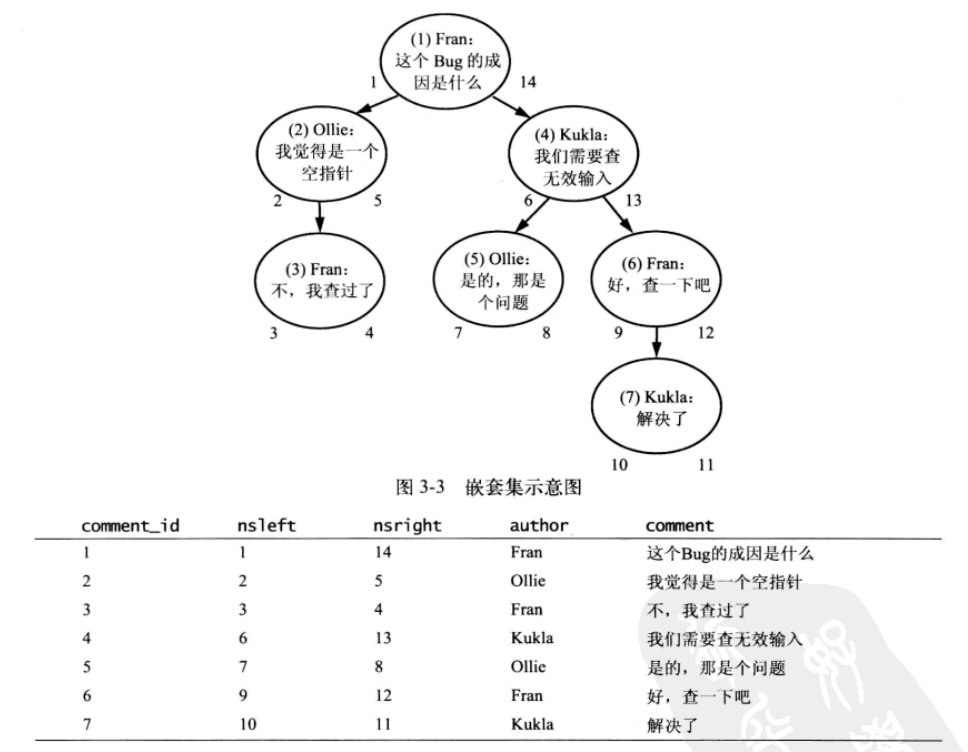
查询评论#4及其所有后代
1 | select c2.* from comment as c1 |
查询评论#6的祖先
1 | select c2.* from comment as c1 |
删除指定节点
可以直接删除,虽然再示例图中,左右两个值时有序的,而每个节点也是和它相邻的父兄节点进行比较,但是嵌套集设计并不必须保证分层关系。并且在你删除某节点后,该节点所有子节点自动上移
查询评论#6的直接父亲
1 | select parent.* from comment as c |
增加,移动节点
这个对于嵌套集要复杂的多,你需要重新计算插入节点的相邻兄弟的节点、祖先节点和祖先节点的兄弟,来确保它们左右值都比这个新节点的左右值大,如果这个节点不是非叶节点,你还需要计算它的子孙节点。
插入一个叶子节点,以下语句将更新每个需要更新的地方
1 | -- make space for NS values 8 and 9 |
总结
优点:查询,简单快速。删除时,原来子节点的关系自动上移。
缺点:
- 查询一个节点的直接上级或下级,很困难。
- 增、改,困难。
3.闭包表:
闭包表是解决分级存储一个简单而优雅的解决办法。
创建另一张叫做tree_path,他包含两列,每一列都是一个指向comment中的comment_id
1 | CREATE TABLE comment( |
将树中任何一对具有祖先-后代关系的节点对都存储在tree_path的一行中,即使他们不是直接的父子关系,同时还增加一行指向自己。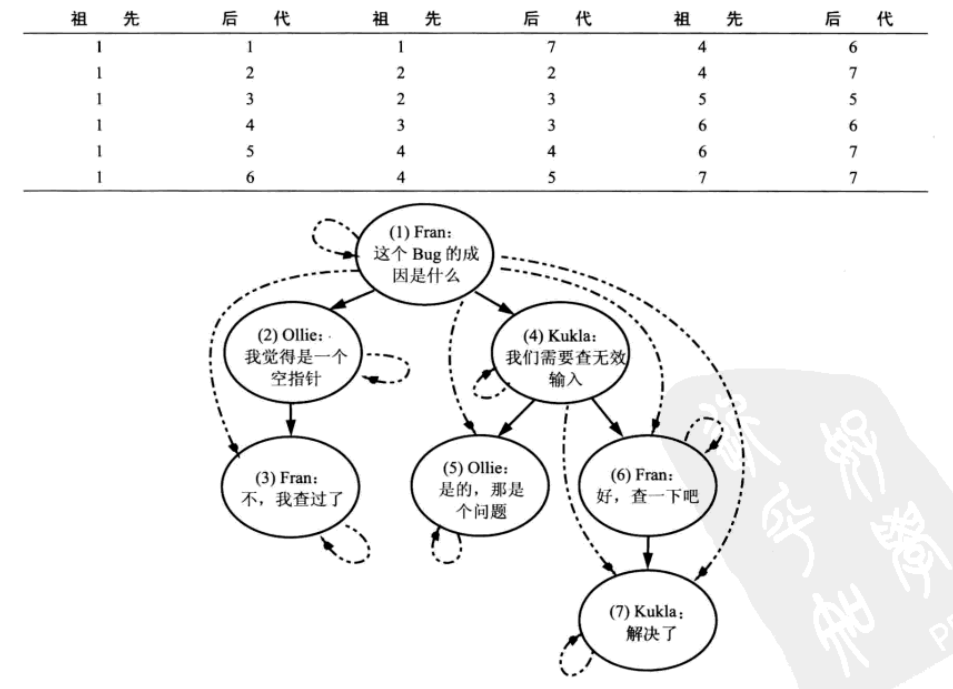
查询评论#4的后代
1 | select c.* from comment as c |
查询评论#6的祖先
1 | select c.* from comment as c |
插入#5下的子节点#8
1 | insert into tree_path(ancestor,descendant) |
删除评论#4
1 | -- 删除直接后代 |
移动,#6从现在的位置(#4的孩子)移动到#3下
1 | -- 删除所有子节点跟他祖先的关系 |
你改使用哪种设计
邻接表
简单高效,如果你的数据库支持WITH或者CONNECT BY PRIOR的递归查询,那么邻接表是最高效的路劲枚举
直观的看到祖先到后代关系,但无法保证引用完整性嵌套集
无法保证引用完整性,太复杂。适用于查询小于非常高场景闭包表
以空间换时间,通用的设计
- 本文链接:https://www.ofcoder.com/2018/06/23/sql/antipatterns/03-%E5%8D%95%E7%BA%AF%E7%9A%84%E6%A0%91/
- 版权声明:Copyright © 并发笔记 - ofcoder.com. Author by far.
分享