redis妙用-hash类型
条评论hash类型,又叫作散列类型,它类似hashmap,通过一定的hash算法得到对应的索引位置,然后将数据保存在该索引所在的地方。本章讲述的东西,重点不在于应用场景,因为hash能做的事情,string也都能做。所以本章分享的是,试图揣测redis官方推出hash的意义,以及实现原理。
api
针对字符串的操作
| 命令 | 说明 |
|---|---|
| HSET key fieId value | 存储一个散列键 |
| HMSETNX key fieId value[fieId value …] | 批量一个key的多个fieId |
| HSETNX key fieId value | 存入一个不存在的散列键 |
| HGET key fieId | 获取key的一个键的值 |
| HMGET key fieId[fieId …] | 批量获取key的值 |
| HDEL key fieId | 删除一个散列键 |
针对数字的操作
| 命令 | 说明 |
|---|---|
| HINCRBY key fieId increment | 对key散列中的fieId进行{increment}的增加 |
应用场景
缓存
像string类型一样,它的第一个应用场景作为缓存,我们考虑一下该表存在redis中怎么存储合适。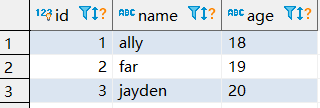
1 | -- 约定key生成规则为 |
hash键意义何在?
看完hash键的api,我们看到hash类型存在的命令,string类型都提供了,就连上面举例的缓存的应用场景,string类型也可以实现,那么这个时候hash类型的意义存在哪里?
- hash键可以将信息凝聚在一起,而不是直接分散的存储在整个redis中,方便管理数据,还可以避免一定的误操作
- 避免键名冲突
- 减少内存/cpu的消耗
这里仅解释第三点,第三点怎么理解,当你给key设置一个过期时间的时候,redis会对所有的key进行扫描它有没有过期,而这种机制只会对hash键的key进行扫描,它的fieId层是不会被扫描的,所以减少的消耗。当你有一批key它们的过期时间一致,你使用string类型,他会扫描所有的key,而使用hash类型,redis只需扫描hash的第一层。
哪些情况不适用hash?
- 需要使用过期功能,过期功能只能使用在key上
- 二进制操作命令不适用hash,如:SETBIT,GETBIT,BITOP
- 需要考虑数据量分布问题
这里仅解释第三点,第三点怎么理解,需要先了解redis集群存储方式(预分配hash槽),redis会将集群分为16384个槽,16384不会根据集群的数量而改变。然后将16384个槽平均分配给每一个redis节点去管理。如图所示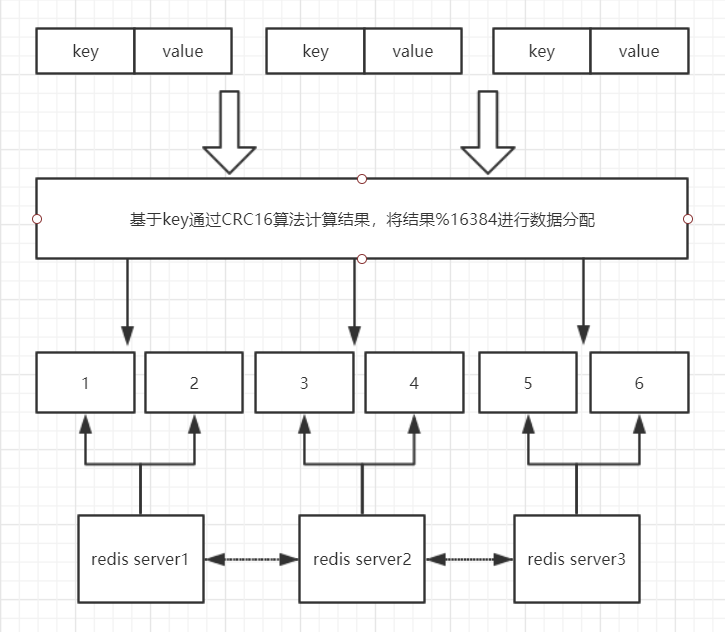
当一个key需要存储时,会对key进行取模计算,得到一个槽的位置,假如这个槽由redis的节点1管理,那么这个key的数据就会真正落在节点1的物理内存上。
这个时候来解释第三点的原因,假如我们使用hash类型,缓存的key约定为以上举例的情况,那么user表的所有数据都会落在某一个节点上,假如这个表的数据有一千万,那么一千万都落在一个节点上,其他的节点上没有数据,这肯定是不合适的。这个节点内存是会撑爆的。
那么回过头来,为什么redis要采用预分配hash槽作为集群管理的方案?
主要是为了解决快速扩缩容的问题。假如我现在新加入一个节点,根据预分配hash槽的方案,该新加入的节点管理的槽为16384,16284…那么redis要做的操作只需将这些槽的数据迁移到新节点上就行了,不用像hashmap那样rehash的操作。
- 本文链接:https://www.ofcoder.com/2019/05/13/middleware/redis%E5%A6%99%E7%94%A8-hash%E7%B1%BB%E5%9E%8B/
- 版权声明:Copyright © 并发笔记 - ofcoder.com. Author by far.
分享