redis妙用-string类型
条评论string类型,是我们最常用的。以及一些特性,我们都比较熟悉,这一节一起回顾一下string的应用场景,以及对这些场景延申的一些思考。
- 缓存,如何设计缓存存储,使用spring cache另当别论
- 分布式锁,锁续期
- 计数器
- 分布式全局序列,减少IO交互提高效率
api
针对字符串的操作
| 命令 | 说明 |
|---|---|
| SET key value | 存储字符串键 |
| MSET key value[key value …] | 批量存储字符串键 |
| SETNX key value | 存入一个存在在的字符串,若存在存储不成功 |
| GET key | 获取一个键的值 |
| MGET key[key …] | 批量获取键的值 |
针对数字的操作
| 命令 | 说明 |
|---|---|
| INCRBY key increment | 对数字key进行{increment}的增加 |
| DECRBY key decrement | 对数字key进行{decrement}的减少 |
| INCR key | 对数字key自增1 |
| DECR key | 对数字key自减1 |
统一的操作
| 命令 | 说明 |
|---|---|
| DEL key[key …] | 删除一个键 |
| EXPIRE key seconds | 设置key的过期时间(秒) |
| PEXPIRE key milliseconds | 设置key的过期时间(毫秒) |
应用场景
缓存
string数据类型,我们常用来做为缓存,一般都是使用spring cache这样的框架来管理缓存。那么考虑一下,在没有使用任何框架情况下,我们使用redis作为缓存,redis中key怎么设计呢?如下表。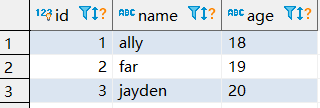
我们第一个会想到使用json、xml来将user的数据序列化之后保存到redis中,但是这样的话,不便于我们做修改操作,对不对。如果我们要修改的话,需要查询出来进行反序列化,才能做修改。
但是如果进行 这一串操作的话,又会产生第二个问题,就是并发情况下,其他线程会读到修改之前的数据。这里多说一句,我们在实际生产中解决这一问题的方案就是对数据做修改时,直接删除缓存,然后别的线程查询时,再写入缓存。
那么有没有其他的设计方式来解决这一问题呢?我们把解决思路放在缓存的key上,在设计缓存key时,制定一个约定熟成的规定来存储,比如
1 | -- 约定key生成规则为 |
分布式锁
分布式锁,通常会用到SETNX、EXPIRE,SETNX用来获取锁,而EXPIRE设置锁的失效时间,防止死锁。如下
1 | SETNX("couponcode::123456", 1) //return 1,成功获得锁 |
那么这个时候其实又会有另一个问题,SETNX和PEXPIRE是分两步执行,那么可能出现SETNX成功了,在执行PEXPIRE时失败了,就会导致死锁。那么redis给我们还提供了一个原子操作。
1 | SET couponcode 1 EX 10 NX //EX 表示失效时间,NX表示不存在则增加 |
以上命令看似完美的解决了分布式锁的问题,既保证了原子性,又解决了死锁的问题。但是我们还忽略了一点,假如我们设置锁的超时时间为10秒,但是我们应用系统处理需要20秒,那么在多余的10秒内将会有其他的线程获得该锁,那么怎么解决呢?
其实对于处理redis的续期,业界比较正确的姿势是采用redisson这个客户端工具,具体可见同性恋交友网站github。
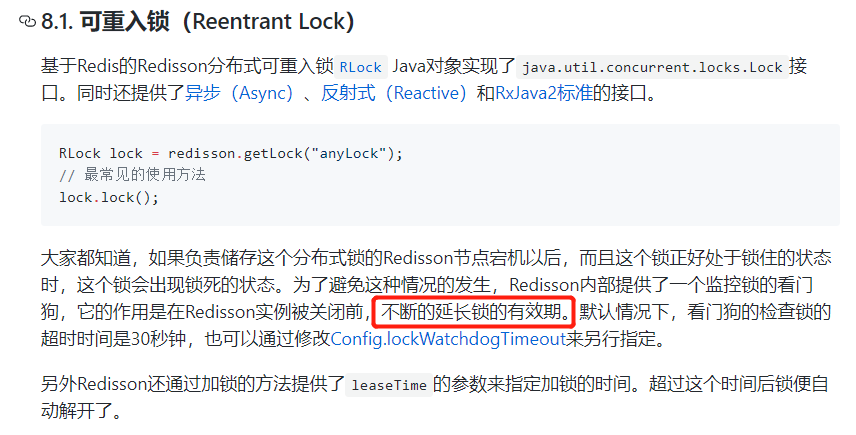
redisson官方文档中,有明确的提到看门狗每30秒钟会帮我们检查锁的时间,并帮助我们续期。那么这时就问题来了,那么假如锁的时间为10秒,而看门狗的检查时间为30秒,那么不就可以有多个线程同时持有锁了嘛,虽然可以通过Config.lockWatchdogTimeout来指定,但是抱着对技术敬畏的心态,我们一起来看看看门狗是怎么实现的。那么我们写一个demo,跟这源码看看
1 | public class RedissonLock { |
至此,一切明白了,redisson在加锁成功后,开启一个定时任务,也是所谓的看门狗。定时任务每次执行会调用renewExpirationAsync(threadId)检查锁是否释放,没有释放则对锁进行续期 renewExpiration()。而定时任务每次调度时间差为internalLockLeaseTime/3,默认锁时间为30秒,那就是10秒。
那么也就是说不会出现我们担心的问题,当我们锁的时间为10秒时,看门狗会在该锁还剩7秒的时候对锁进行续期。
计数器
以下场景,我们要对每一个文章的阅读量进行统计
如果使用数据库要统计的话,我们将面对两个问题,并发修改和数据库压力。处理并发我们可以用cas,那么面对数据库压力我们毫无办法。这是我们可以使用redis提供的incr命令进行统计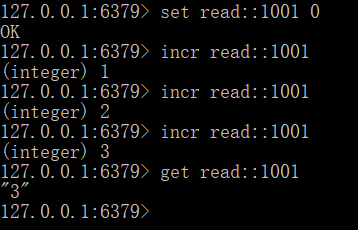
分布式全局序列
在你的业务系统到达一定的体量,特别是进行了分库分表后,分布式唯一键就显得尤为重要,原先的数据库自增id一定是用不了了。常规的解决办法我们多多少少有了解过,雪花算法,UUID。当然这里主要介绍redis生成全局唯一键,使用incr命令生成。
那么使用redis的incr就可以实现了啊,为什么还要单独拿出来说呢?其实使用incr命令会存在一个问题,那就是IO交互次数过多,想一想在分布式情况,尽管处于同一内网,还是会存在网络问题,过的IO交互就会影响效率,那么有没有解决办法呢?
redis官方其实有考虑到这一点,解决IO交互次数过多的办法就是,一次性获取多个唯一键,那就是incrby,他可以一其增加多个值
1 | incrby read::1001 5 |
那么这种方案,虽然解决了IO交互次数,那么假如系统宕机了,我们就会丢失已经获取的那一段id值,所以在你的需求要求id连续的情况下,不建议采用这种方式。
- 本文链接:https://www.ofcoder.com/2019/05/11/middleware/redis%E5%A6%99%E7%94%A8-string%E7%B1%BB%E5%9E%8B/
- 版权声明:Copyright © 并发笔记 - ofcoder.com. Author by far.
分享