SQL反模式13-乱用索引
条评论目的:优化性能
改善性能最好的技术就是合理使用数据库中的索引。索引也是数据结构,他可以帮助快速定位到相应的行,而不需要野蛮的自上而下全表遍历。
反模式:无规划的使用索引
软件开发人员通常猜测的来选择索引,那么就不可避免的犯一些错误
- 不使用索引或索引不足
- 使用了太多索引或者使用了一些无效的索引
- 执行一些让索引无能为力的查询
无索引
通常我们知道数据库为了保持同步索引会增加额外的开销。每一次insert,update,数据库不得不更新索引的数据结构来保证数据一致。
我们已经习惯额外的开销都是浪费的。但却忽略了一个事实,索引能够带给你的好处远远大于它的开销。除了在你select的时候能够快速定位数据。在你update,delete时,索引也能帮你快速找到你要更新的数据。如下SQL,bug_id的索引能有效的提升效率。
1 | update bug set status = 'FIXED' where bug_id = 1234 |
索引太多
你只有在使用索引查询时才能收益。对于那些你不使用的索引,你没有任何好处。
1 | create table bug( |
这个例子中,有几个无用的索引:
- bug_id:为主键,数据库会自动为主键创建索引,因此再定义一个索引就是冗余的操作,这个索引没有任何好处。
- summary:对于长字符串,比如varchar(80)这种类型的索引要比更为紧凑数据类型的索引大很多。而且你好像不可能使用summary进行全匹配查找。
- hour:你不太可能按照特定的值去搜索的列
- bug_id, date_report, status:使用组合查询是一个很好的选择,但大多数人创建的组合索引通常都是冗余索引或很少使用。同样的,组合索引的列的顺序也是很重要的:你需要在查询条件,联合条件或者排序规则上使用定义索引时的从左到右的顺序。
索引也无能为力
接下来常犯的错误就是进行一个无法使用索引的查询。
比如电话簿是按照先姓后名的方式对联系人排序的,就像一个按照last_name,first_name顺序创建的联合索引一样,这种索引不能帮你按照名来进行快速查找。
1 | create index telephone_book on account(last_name, first_name); |
那么以下查询无法使用索引
- select * from telephone_book order by first_name, last_name;
这个查询就是上面说的,如果你创建了一种先last_name再first_name顺序的索引,那么它是不会帮你先按照first_name进行排序的。 - select * from bug where MONTH(date_report) = 4;
即使你为date_report创建了索引,因为在索引中是按照完整的日期来进行排序的,所以你想单独使用它的月份查询是不行的。 - select * from telephone_book where last_name = ‘Charles’ or first_name = ‘Charles’;
你定义的是联合索引,那么索引是根据两列进行排序的,所以你无法按照其中某一项来使用索引查询。 - select * from bug where description lisk ‘%crash%’
即使你为description定义了索引,由于这个查询断言的匹配字串可能出现在该字段的任何部分,因此索引结构也帮不上忙。
如何识别反模式
当出现以下情况时,可能是反模式
- 这是我的查询语句,怎样使它更快?
- 我在每个字段上都定义了索引,为什么它没有变的更?
- 我听说索引会使数据库变慢,所以我不使用它。
合理使用反模式
如果你需要设计一个普通的数据库,不了解那些查询时需要重点优化的,你就不能确定哪些索引是最好的。你需要大胆的猜测,你可能创建一些无用的索引,但是你必须去尝试。
分离率是衡量索引的一个指标,它是一张表中,所有不重复的数量和总记录条数之比:
1 | select count(distinct status) / count(status) from bug; |
分离率越低,索引效率就越低,你需要时刻关注,并抛弃哪些低效的索引。
解决方案:MENTOR你的索引
MENTOR:测量(Measure),解释(Explain),挑选(Nominate),测试(Test),优化(Optimize),重建(Rebuild)
测量
大多数据库都提供一些方法来记录执行SQL查询的时效,那么就可以定位到哪些SQL最耗时,并优化。
- Oracle 和 SQL Server都有SQL跟踪功能和工具来生成分析相应报表,SQLServer 称之为 SQL Server Profiler,Oracle称之为TKProf。
- MySQL 和 PostgreSQL 会记录耗时超过一个特定值的查询请求。MySQL称之为慢查询日志,其配置文件中long_query_time项默认为10秒。PostgreSQL有一个类似的配置叫做log_min_duration_statement。
- postgreSQL还有一个配套的工具叫做pgFouine,它能帮助你对查询日志进行分析,并且定位出哪些需要格外注意的查询请求
你在做以上操作进行优化时,记得禁止所有缓存,他会影响数值。分析完后记得关闭profiler,或降低profiler运行的频率。
解释
找到了最耗时的SQL,接下来就是要找出它之所以慢的原因。每个数据都使用一种优化工具为每次查询选择合适索引。你可以让数据库生成一份它所作做分析的报表。
每种数据库的语法不尽相同。
| 数据库 | QEP报表方案 |
|---|---|
| IBM DB2 | EXPLAIN, db2expln命令, Visual Explain |
| SQL Server | SET SHOWPLAN_XML, Display Execution plan |
| MySQL | EXPLAIN |
| Oracle | EXPLAIN PLAN |
| PostgreSQL | EXPLAIN |
| SQLite | EXPLAIN |
看一个简单QEP报表(MySQL)。
1 | EXPLAIN select bug.* from bug |
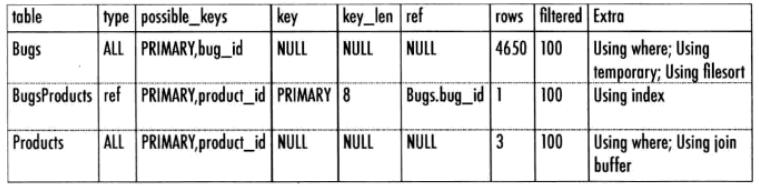
结果中的key这一列表明这个查询使用的索引。
like表达式,强制bug表中进行全表遍历。
product.product_name列上没有索引,我们可以建立索引增加效率。
挑选
有了报表,你应该挑选出哪些被你漏掉的但能起到比较好效果的索引。数据库都有提供一些工具,你可以详细了解一下,如:
- IBM DB2 Design Advisor
- SQL Server Database Engine Tuning Advisor
- MySQL Enterprise Query Advisor
- Oracle Automatic SQL Tuning Advisor
索引覆盖
这是一个额外的话题,但是他能极大提升效率。
如果一个索引包含我们所需要的所有列,那么就不需要再从表中获取数据了。
想象一下,如果电话簿中的条目只包含一个页码,在你找到一个名字后,你不得不翻到对应的页码才能获取所需要的号码。如果将这两步整和成一步是不是会更合理,由于电话簿是排序的,所以找到一个名字很快的,然后在一个条目中可以包含一个字段存储电话号码,甚至地址。
这就是索引覆盖的作用,你可以定义一个索引包含额外的列,即使这些列对于这个索引来说并不是必须包含的。
1 | -- 1 |
如果你定义的索引是1,那么查询语句2就不用去表中查询了,直接在索引的数据结构中就能获取结果,因为查询语句2所查询的所有的列都包含在索引中。
测试
这一步很重要,在创建完索引后,并不是万事大吉,你需要跟踪那些查询,需要确认你的改动确实提升了性能,然后才能确定工作完成。
优化
索引是小型的、频繁使用的数据结构,因此很适合常驻内存,毕竟内存操作比磁盘IO要快很多倍。
数据库服务允许你配置缓存所需要的系统内存大小,大多数默认配置都是最小的。所以你需要调整这个值。
使用索引预加载方法可能要比通过数据库活动本身将最频繁使用的数据与索引放入缓存更有效一点。比如MySQL中,使用LOAD INDEX INTO CACHE 语句。
重建
索引在平衡的时候效率是最高的,当你更新或删除时,索引就会不平衡,就如文件系统中随着时间推移产生很多磁盘碎片一样。所以你想最大限度的使用索引,就必须定期对索引进行维护。
每个数据库维护索引的语句都有区别
| 数据库 | 索引维护命令 |
|---|---|
| DB2 | REBUILD INDEX |
| SQL Server | ALTER INDEX … REORGANIZE, ALTER INDEX … REBUILD, or DBCC DBREINDEX |
| MySQL | ANALYZE TABLE or OPTIMIZE TABLE |
| Oracle | ALTER INDEX … REBUILD |
| PostgreSQL | VACUUM or ANALYZE |
那么多久重建一次索引?这个需要你自己定夺。至于花上一小时时间来重构一个使用很少的索引,获得1%的性能提升,这个也没有必要。
总结
了解你的数据,了解你的查询请求,然后MENTOR你的索引。
- 本文链接:https://www.ofcoder.com/2018/09/02/sql/antipatterns/13-%E4%B9%B1%E7%94%A8%E7%B4%A2%E5%BC%95/
- 版权声明:Copyright © 并发笔记 - ofcoder.com. Author by far.
分享