SQL反模式06-实体-属性-值
条评论目的:支持可变的属性
可扩展性是程序员所追求的。通常一张表对应一个实体,但是需求中也可能两个实体他们继承同一个父类实体,他们由相同的属性,也有不同属性。
bug和feature_request,有相同的属性,我们抽出一个父类issue。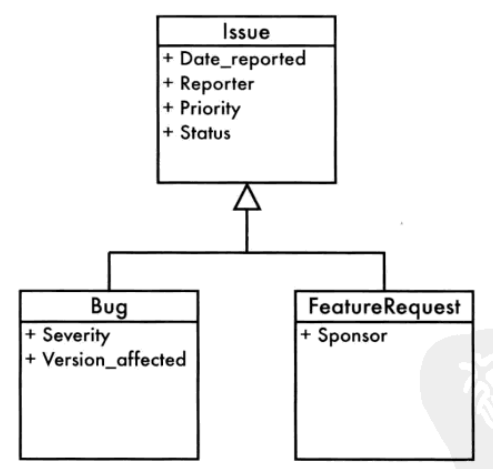
反模式:使用泛型属性表(EVA)
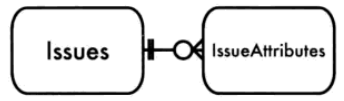
对于程序员来说,需要支持可变的属性时,第一发应就是创建一张表(issue_attributes),它有三个字段
- 实体 : 指向父表的外键
- 属性 : varchar类型,存储属性名字
- 值 :存储对应属性的值
1
2
3
4
5
6
7
8
9
10create table issue(
issue_id serial primary key
);
create table issue_attribute(
issue_id bigint unsigned not null,
attr_name varchar(100) not null,
attr_value varchar(100) not null,
primary key(issue_id, attr_name),
foreign key(issue_id) references issue(issue_id)
);
查询某一个属性
假如你要查询bug的描述信息,显得比较啰嗦,还不清晰
1 | select issue_id, attr_value as 'description' from issue_attribute where attr_name = 'description' |
数据完整性
你无法保证attr_value是否是一个有效值
无法声明属性类型
无法使用SQL的数据类型,比如对日期、金钱等格式内容都只能保持为字符串类型;
无法确保引用完整性
你不能对attr_value声明外键约束,比如说status,你不能保证status的值一定存在status表中
无法确定属性名
假如有两条数据,一条的attr_name是sex,一条attr_name是gender,都是表示性别
查询结果中有多个属性时,异常困难
1 | select i.issue_id, |
如何识别反模式
当出现以下情况时,可能是反模式
- 数据库不需要修改元数据库(表中的列属性)就可以扩展。还可以在运行时定义新的属性。
- 查询是连接数量非常多,且连接的数量可能会达到数据库的限制时,你的数据库的设计可能是有问题的。
- 普通的报表查询变的及其复杂甚至不且实际。
合理使用反模式
优点:
- 表中的列很少;
- 新增属性时,不需要新增列。不会影响现有表的结构;
- 存储的字段内容不会为空值。
缺点:上面列了一大段
如果真的有非关系数据管理需求,那最好使用nosql数据库
解决方案:模型化子类型
单表继承
所有属性都在一个单表上保存,使用issue_type来标识哪一个子类,子类属性必须支持null。
缺点:
- 当程序加入新对象时,必须修改数据库来适应这些新对象,而张表的列的数量是有限制的。
- 没有任何的元信息来记录哪个属性属于哪个子类型。
实体表继承
为每个子类型创建一张独立的表,每个表包含哪些属于基类的共有属性,同时也包含了子类型特殊化的属性。
优点:
- 你可以像使用普通表那样来使用
- 相比于单表继承,新增对象时,你只需要新增表,而不需要修改之前的表结构
缺点:
- 难将通用属性和子类特有属性区分开来。因此,如果将一个新的属性增加到通用属性中,必须为每个子类表都添加一遍。
类表继承
把表当成面向对象里的类,这可能也是最容易想到的吧,创建一张基表存储子类相同的字段,每一个子类创建一张表,添加一列执行基表的外键
半结构化数据模型
如果有很多子类型或者必须经常增加新的属性支持,那么可以用一个BLOB列来存储JSON数据,缺点是,这样的结构中sql无法获取某个指定的属性。你必须或者整个blob字段并通过程序去解释这些属性。
当你需要绝对的灵活性时,可以使用这个方案。
你接手一个EAV项目
你无奈接手一个EAV项目,你需要衡量在数据库中处理数据好还是在程序代码中处理好,比如说查询
1 | select * from issue_attribute where issue_id = 1444; |
查出所有行,在程序代码中遍历,明显要比在数据库中使用无限的联结查询要好。
- 本文链接:https://www.ofcoder.com/2018/07/21/sql/antipatterns/06-%E5%AE%9E%E4%BD%93-%E5%B1%9E%E6%80%A7-%E5%80%BC/
- 版权声明:Copyright © 并发笔记 - ofcoder.com. Author by far.
分享